欢迎来到体验的时代
David Silver, Richard S. Sutton
这是强化学习之父 Sutton 在 2025 年和另一个强化学习科学家 Silver 一起发布的一篇文章。原文在这里。为了准备工信部的分享,更加深刻领会这二位的思想,我把原文做了翻译。
中文翻译:刑无刀+DeepSeek
摘要
我们正站在一个人工智能新时代的门槛前,这个时代有望实现前所未有的能力水平。新一代智能体将通过主要从体验中学习,来获得超越人类的能力。本文探讨了即将定义这个新时代的关键特征。
人类数据时代
近年来,人工智能通过在海量人类生成的数据上进行训练,并结合专家示例与人类偏好进行微调,取得了显著进步。大型语言模型是这种方法的典范,它们实现了广泛的通用性。如今,单个大型语言模型就能完成从写诗、解决物理问题到诊断医疗病症、总结法律文件等各种任务。
然而,虽然模仿人类足以将许多人类能力复现到合格水平,但仅靠这种方法尚未、也大概率无法在众多重要领域和任务中实现超越人类的智能。在数学、编程和科学等关键领域,从人类数据中提取的知识正迅速接近极限。大多数高质量数据源——即那些真正能够提升强大智能体性能的数据——要么已被耗尽,要么即将被耗尽。仅靠从人类数据进行监督学习所驱动的进步速度明显放缓,这标志着我们需要一种新方法。此外,有价值的新见解,例如新定理、新技术或科学突破,超出了当前人类理解的边界,无法被现有人类数据所捕捉。
体验时代
要取得重大进展,我们需要新的数据来源。这种数据必须以这样一种方式生成:它能随着智能体变得更强而持续改进;任何静态的合成数据生成程序都会很快被超越。这可以通过让智能体持续从它们自身的体验中学习来实现,即由智能体与环境互动所产生的数据。人工智能正处在一个新时代的开端,在这个时代,体验将成为改进的主导媒介,并最终使当今系统所使用的人类数据规模相形见绌。
这一转变可能已经开始了,即使对于体现以人类为中心的人工智能的大型语言模型也是如此。数学能力就是一个例子。AlphaProof [20] 最近成为第一个在国际数学奥林匹克竞赛中获得奖牌的程序,其表现超越了以人类为中心的方法 [27, 19]。在初步接触了人类数学家多年创建的约十万个形式化证明后,AlphaProof 的强化学习算法随后通过与一个形式化证明系统的持续互动,额外生成了上亿个证明(脚注 1)。这种对互动体验的关注使得 AlphaProof 能够探索超越现有形式化证明限制的数学可能性,从而为新颖且具有挑战性的问题找到解决方案。非形式化数学领域也通过用自我生成的数据替代专家生成的数据取得了成功;例如,DeepSeek 近期的研究“凸显了强化学习的力量与美感:我们不是明确地教导模型如何解决问题,而是简单地为其提供正确的激励,它便能自主地发展出高级的问题解决策略。”[10]
我们的论点是,一旦体验学习的全部潜力被释放,惊人的新能力将会出现。这个体验时代很可能将以智能体和环境为特征,它们除了从海量的体验数据中学习外,还将在以下几个维度上突破以人类为中心的人工智能系统的限制:
- 智能体将栖身于体验流之中,而非短暂的交互片段。
- 它们的行动和观察将深深植根于环境,而非仅仅通过人类对话进行互动。
- 它们的奖励将基于它们在环境中的体验,而非来自人类的预先判断。
- 它们将基于体验进行规划和/或推理,而非仅仅用人类的术语进行推理。
我们相信,当今的技术,辅以恰当选择的算法,已经为实现这些突破提供了足够强大的基础。此外,人工智能界对这一议程的追求将催生这些方向上的新创新,从而快速推动人工智能迈向真正超越人类的智能体。
体验流
一个拥有体验的智能体可以终生持续学习。在人类数据时代,基于语言的人工智能主要专注于短期的交互片段:例如,用户提出一个问题,智能体(或许经过几步思考或工具使用后)给出回应。通常,信息很少或完全不会从一个片段延续到下一个片段,这排除了任何随时间推移而进行的适应性调整。此外,智能体的目标完全局限于当前片段内的结果,比如直接回答用户的问题。相比之下,人类(和其他动物)则存在于一个持续多年、不断推进的行动与观察之流中。信息在整个流中传递,他们的行为根据过去的体验进行自我调整、纠正和改进。此外,目标可以通过延伸到流之未来的行动和观察来设定。例如,人类可能选择某些行动来实现长期目标,比如改善健康、学习一门语言,或取得科学突破。
强大的智能体应该拥有自己不断推进的体验流,像人类一样在很长的时间尺度上展开。这将使智能体能够采取行动以实现未来目标,并能随着时间的推移持续适应新的行为模式。例如,一个连接到用户可穿戴设备的健康与保健代理,可以持续数月监测睡眠模式、活动水平和饮食习惯。然后,它可以基于长期趋势和用户特定的健康目标,提供个性化的建议、鼓励,并调整其指导。同样,一个个性化教育智能体可以跟踪用户学习新语言的进度,识别知识漏洞,适应其学习风格,并在数月甚至数年内调整其教学方法。再者,一个科学家智能体可以追求雄心勃勃的目标,例如发现一种新材料或减少二氧化碳排放。这样的智能体可以在很长时期内分析现实世界的观测数据,开发和运行模拟,并提出现实世界的实验或干预措施。
在每一种情况下,智能体都会采取一系列步骤,以最大化其在指定目标上的长期成功。单个步骤可能不会带来任何即时收益,甚至在短期内可能是有害的,但从总体上看,它可能为长期成功做出贡献。这与当前的人工智能系统形成了鲜明对比,后者只是对请求提供即时响应,而没有任何能力去衡量或优化其行为对环境的未来影响。
行动与观察
体验时代的智能体将在现实世界中自主行动。人类数据时代的大型语言模型主要专注于人类专属的操作和观察,即向用户输出文本,并将来自用户的文本输入回智能体。这与自然智能截然不同,在自然智能中,动物通过运动控制和传感器与环境互动。虽然动物(尤其是人类)可能与其他动物交流,但这是通过与其他感觉运动控制相同的接口进行的,而非通过专属通道。
人们早已认识到,大型语言模型也可以在数字世界中“行动”,例如通过调用API(例如参见[43])。最初,这些能力主要来自人类使用工具的示例,而非来自智能体的体验。然而,编程和使用工具的能力已日益建立在执行反馈之上[17, 7, 12],即智能体实际运行代码并观察发生的情况。最近,新一轮的原型智能体开始以更通用的方式与计算机交互,即使用人类操作计算机的相同界面[3, 15, 24]。这些变化预示着从纯粹的人类专属通信,向更为自主的交互方式转变,智能体能够在世界中独立行动。这类智能体将能够积极探究世界,适应不断变化的环境,并发现可能从未出现在人类思维中的策略。
这些更丰富的交互方式将提供一种自主理解和控制数字世界的手段。智能体可以使用“对人类友好”的操作和观察方式,例如用户界面,这自然有助于与用户沟通和协作。智能体也可以采取“对机器友好”的操作,如执行代码和调用API,使其能够为实现目标而自主行动。在体验时代,智能体还将通过数字接口与现实世界互动。例如,一个科学家智能体可以监测环境传感器,远程操控望远镜,或在实验室中控制机械臂以自主进行实验。
奖励
如果体验式智能体不仅可以从人类偏好,还能从外部事件和信号中学习,会怎样呢?
以人类为中心的大型语言模型通常根据人类预判来优化奖励:由专家观察智能体的行为并判断其是否得当,或在多个备选行为中选出最佳方案。例如,专家可能会评判健康助理的建议、教育助手采用的教学方式,或科学家智能体提出的实验方案。这些奖励或偏好是由人类在未考虑其实际后果的情况下决定的,而非衡量这些行为对环境产生的影响,这意味着它们并未直接植根于现实世界。依赖这种人类预判通常会为智能体的性能设置一个难以突破的上限:智能体无法发现那些被人类评估者低估的更好策略。
为了发现远超现有人类知识的新思路,有必要使用基于现实的奖励——即来源于环境本身的信号。例如,健康助手可以根据用户的静息心率、睡眠时长和活动水平等信号组合,将用户的健康目标转化为奖励;而教育助手则可以使用考试成绩为语言学习提供基于现实的奖励。类似地,一个以减少全球变暖为目标的科学家智能体,可以采用基于二氧化碳浓度实证观测的奖励;而旨在发现更强材料的目标,则可以结合材料模拟器的测量结果(如抗拉强度或杨氏模量)来设定奖励。
基于现实的奖励也可能来自部分人类,那些作为智能体的环境一部分的人类(脚注 2)。例如,人类用户可以报告蛋糕是否可口、运动后的疲劳程度或头痛的疼痛级别,从而使辅助智能体能够提供更好的食谱、完善健身建议或改进推荐药物。这类奖励衡量的是智能体行为在其环境中产生的结果,最终应能提供比人类专家预先评判蛋糕食谱、锻炼计划或治疗方案更好的辅助。
如果奖励不是来自人类数据,那它们从何而来?一旦智能体通过丰富的行动和观察空间与世界连接,将不缺乏基于现实的信号来作为奖励的基础。事实上,现实世界中充斥着各种可量化的指标,例如成本、错误率、饥饿感、生产率、健康指标、气候指标、利润、销售额、考试成绩、成功率、访问量、产量、库存、点赞数、收入、愉悦感/痛感、经济指标、准确率、功率、距离、速度、效率或能耗。此外,还有无数从特定事件的发生,或从原始观察与行为序列中衍生出的特征信号。
原则上,我们可以创建多种不同的智能体,每个智能体以某个基于现实的信号作为其奖励进行优化。有观点认为,即便只是一个这样的奖励信号,只要能非常有效地进行优化,可能就足以催生具有广泛能力的智能[34](脚注 3)。这是因为在复杂环境中实现一个简单的目标,往往需要掌握多种多样的技能。
然而,追求单一的奖励信号表面上看似乎不符合通用人工智能的要求——即能够可靠地引导智能体实现任意用户期望的行为。那么,对基于现实的、非人类的奖励信号进行自主优化,是否与现代人工智能系统的要求背道而驰呢?我们认为并不必然如此,并在此概述一种可能满足这些需求的方法;其他方法也可能存在。
其核心思想是,以用户引导的方式,基于现实世界的信号,灵活地调整奖励。例如,奖励函数可以定义为一个神经网络,它以智能体与用户及环境的交互作为输入,并输出一个标量奖励。这使得奖励能够根据用户目标,以特定的方式选择或组合来自环境的信号。例如,用户可能设定一个宽泛的目标,如“改善我的体能”,奖励函数则可能返回一个基于用户心率、睡眠时长和步数的函数。或者,用户设定“帮助我学习西班牙语”的目标,奖励函数就可以返回用户的西班牙语考试成绩。
此外,用户可以在学习过程中提供反馈,例如他们的满意度,这些反馈可用于微调奖励函数。奖励函数随后可以随时间进行自适应,改进其选择或组合信号的方式,并识别和纠正任何偏差。这也可以理解为一个双层优化过程:高层优化用户反馈作为顶层目标,底层优化来自环境的基于现实的信号(脚注 4)。通过这种方式,少量的人类数据可能促进大量的自主学习。
规划与推理
体验时代会改变智能体规划和推理的方式吗?近来,利用大型语言模型进行推理或“思考”已取得显著进展[23, 14, 10],即在输出回应前遵循一个思维链[16]。从概念上讲,大型语言模型可以充当一台通用计算机[30]:它能将可计算符号(即tokens)追加到自身的上下文中,从而允许其在输出最终结果前执行任意算法。
在人类数据时代,这些推理方法被明确设计来模仿人类思维过程。例如,人们通过提示引导大型语言模型产生类人的思维链[16]、模仿人类思考的痕迹[42],或者强化与人类示例相匹配的思考步骤[18]。推理过程还可以进一步微调,以产生与正确答案相匹配的思考痕迹,这个正确答案由人类专家确定[44]。
然而,人类语言极不可能提供通用计算机的最佳实例。更高效的思维机制必然存在,它们可能使用非人类的语言,例如利用符号化、分布式、连续或可微分计算。一个自学习系统原则上可以通过从体验中学习如何思考,来发现或改进这类方法。例如,AlphaProof学会了以与人类数学家截然不同的方式,形式化证明复杂定理[20]。
此外,通用计算机的原则只涉及智能体的内部计算;它并未将其与外部世界的现实联系起来。一个被训练来模仿人类思想甚至匹配人类专家答案的智能体,可能会继承深深嵌入该数据中的错误思维方法,例如有缺陷的假设或固有的偏见。举例来说,如果一个智能体接受了用5000年前的人类思想和专家答案进行推理的训练,它可能会用万物有灵论来思考一个物理问题;1000年前,它可能会以有神论的方式进行推理;300年前,它可能会用牛顿力学术语来推理;而50年前则会用量子力学的术语。要超越每一种思维方法,都需要与现实世界互动:提出假设、进行实验、观察结果并据此更新原理。同样,一个智能体必须植根于现实世界的数据,才能推翻错误的思维方法。这种“植根”提供了一个反馈循环,使智能体能够根据现实检验其继承的假设,并发现不受当前主流人类思维模式限制的新原理。没有这种植根,无论多么复杂的智能体,都将成为现有人类知识的回音室。要超越这一点,智能体必须积极与世界互动,收集观测数据,并利用这些数据迭代地完善其理解,这在很多方面都反映了推动人类科学进步的进程。
将思考直接植根于外部世界的一个可能方法是构建一个世界模型[37],用以预测智能体行为对世界产生的后果,包括预测奖励。例如,一个健康助理在考虑推荐一个本地健身房或一个健康播客时,其世界模型可以预测用户的后续心率和睡眠模式会如何变化,同时也能预测与用户未来的对话。这使得智能体能够直接根据自身行为及其对世界的因果影响来进行规划[36, 29]。随着智能体在其体验流中持续与世界互动,它的动态模型也不断更新,以纠正预测中的任何错误。有了世界模型,智能体就可以应用可扩展的规划方法来提高其预测性能。
规划方法与推理方法并不相互排斥:智能体可以应用内部的大型语言模型计算,在规划过程中选择每一个行动,或者模拟和评估这些行动的后果。
为何是现在?
从体验中学习并非新鲜事。强化学习系统此前已掌握大量复杂任务,这些任务都在模拟器中呈现,并具有清晰的奖励信号(大致对应图1中的“模拟时代”)。例如,强化学习方法通过自我对弈,在双陆棋[39]、围棋[31]、国际象棋[32]、扑克[22, 6]和Stratego[26]等棋盘游戏中达到或超越了人类水平;在Atari[21]、《星际争霸II》[40]、《Dota 2》[4]和《GT赛车》[41]等电子游戏中也是如此;在如魔方[1]的灵巧操作任务,以及如数据中心冷却[13]的资源管理任务上也取得了成功。此外,像AlphaZero[33]这样强大的强化学习智能体,在神经网络规模、互动体验量和思考时间长度方面都展现出令人印象深刻且可能无限的扩展能力。
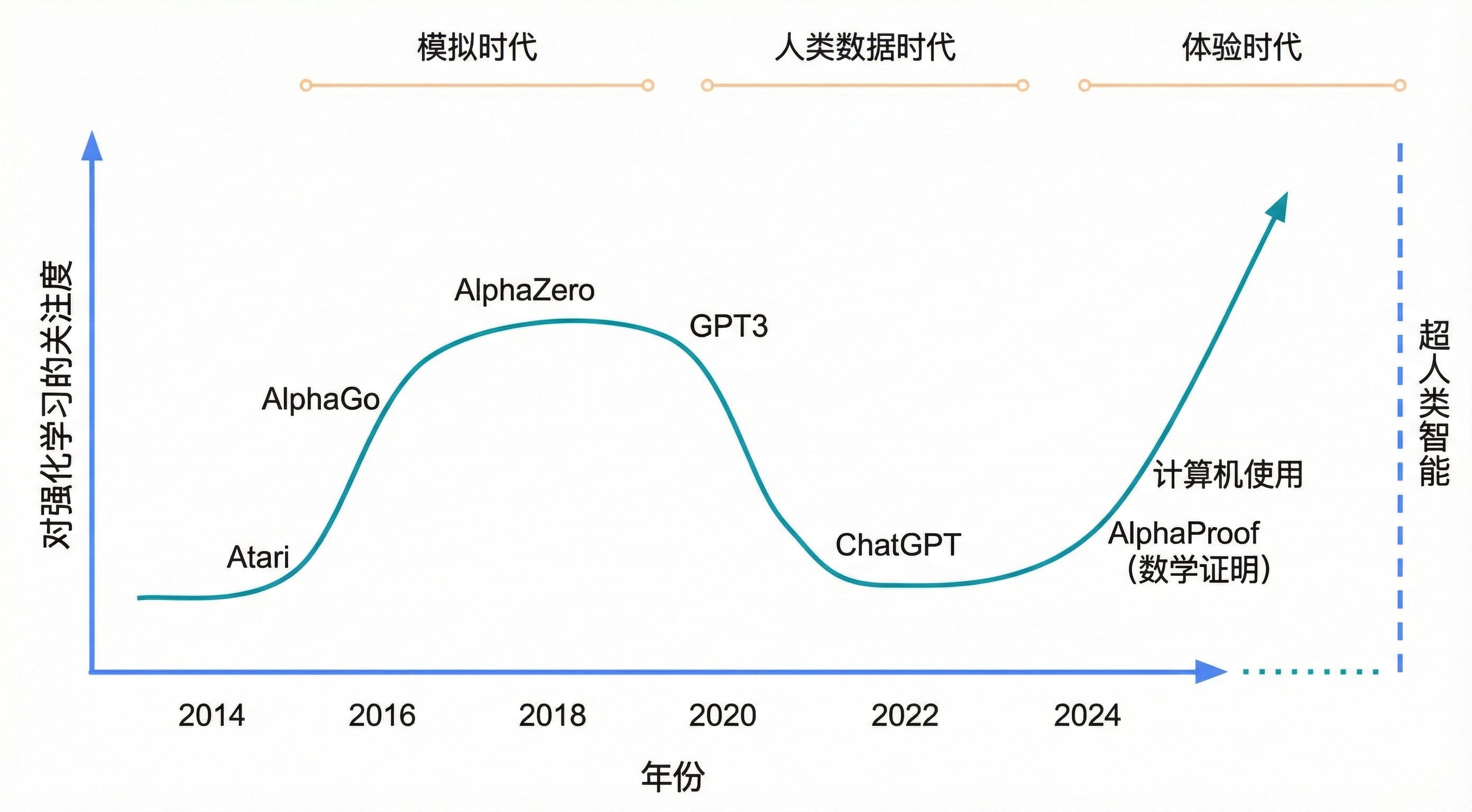
然而,基于此范式的智能体并未跨越从模拟(具有单一、精确定义奖励的封闭问题)到现实(具有多个看似定义不清的奖励的开放性问题)的鸿沟。
人类数据时代提供了一个诱人的解决方案。海量的人类数据语料库包含了应对极其多样化任务的自然语言示例。与模拟时代较为狭隘的成功相比,基于这些数据训练的智能体获得了广泛的能力。因此,体验式的强化学习方法在很大程度上被舍弃,人们转而青睐更通用的智能体,这导致了向以人类为中心的人工智能的广泛转变。
但是,在这种转变中,我们失去了一样东西:智能体自我发现知识的能力。例如,AlphaZero发现了国际象棋和围棋的全新根本性策略,改变了人类玩这些游戏的方式[28, 45]。体验时代将把这种能力与人类数据时代所达到的任务通用性水平结合起来。如上文所述,当智能体能够在现实世界的体验流中自主行动和观察[11],并且奖励可以灵活连接到大量基于现实的真实世界信号时,这将成为可能。能够与复杂的真实世界行动空间互动的自主智能体的出现[3, 15, 24],加上能够解决丰富推理空间中开放式问题的强大强化学习方法[20, 10],都表明向体验时代的过渡已近在眼前。
强化学习方法
强化学习拥有悠久的历史,其根基深植于自主学习,即智能体通过与环境的直接互动自行学习。早期的强化学习研究催生了一系列强大的概念和算法。例如,时序差分学习[35] 使智能体能够预测未来奖励,并带来了诸如在双陆棋中实现超越人类水平表现[39]等突破。基于乐观或好奇心驱动的探索技术被开发出来,以帮助智能体发现创造性的新行为,避免陷入次优的常规[2]。像 Dyna算法 这类方法使智能体能够构建世界模型并从中学习,从而对未来行动进行规划和推理[36, 29]。选项以及选项内/选项间学习(inter/intra-option)等概念促进了时间抽象,使智能体能够在更长时间尺度上进行推理,并将复杂任务分解为可管理的子目标[38]。
然而,以人类为中心的大型语言模型的兴起,将焦点从自主学习转移到了利用人类知识上。诸如 RLHF(基于人类反馈的强化学习)[9,25] 以及将语言模型与人类推理对齐的方法[44]被证明极其有效,推动了人工智能能力的快速进步。这些方法虽然强大,却常常绕过了强化学习的核心概念:RLHF通过调用人类专家来替代机器估算的价值,从而绕过了对价值函数的需求;人类数据提供的强大先验降低了对探索的依赖;而用人类术语进行推理则减少了对世界模型和时间抽象的需求。
但是,可以说这种范式的转变有些矫枉过正。虽然以人类为中心的强化学习实现了前所未有的行为广度,但它也为智能体的性能设置了新的上限:智能体无法超越现有人类知识。此外,人类数据时代主要关注那些为短期的、非现实基础的人类交互片段而设计的强化学习方法,这些方法并不适用于长期的、基于现实的自生互动流。
体验时代提供了一个契机,让我们可以重新审视并改进经典的强化学习概念。这个时代将带来关于奖励函数的新思路,这些函数将灵活地植根于观测数据。它将重新审视价值函数以及从尚未完成的长期数据流中对其进行估算的方法。它将带来有原则且实用的现实世界探索方法,以发现与人类先验知识截然不同的新行为。新颖的世界模型方法将被开发出来,以捕捉基于现实的复杂互动。新的时间抽象方法将使智能体能够以体验为基础,在更长远的时间跨度上进行推理。通过在强化学习的基础上进行构建,并将其核心原理调整以适应新时代的挑战,我们可以释放自主学习的全部潜力,并为通往真正超越人类的智能铺平道路。
影响
体验时代的到来——人工智能智能体从与世界的互动中学习——预示着一个与我们以往所见截然不同的未来。这一新范式虽然提供了巨大的潜力,但也带来了需要仔细权衡的重要风险和挑战,包括但不限于以下几点。
从积极的方面看,体验式学习将释放前所未有的能力。在日常生活中,个性化助理将利用持续的体验流,在数月或数年的时间里,针对个人的健康、教育或职业需求进行调整,以服务于长期目标。或许最具变革性的将是科学发现的加速。人工智能智能体将在材料科学、医学或硬件设计等领域自主设计和进行实验。通过持续从自身实验结果中学习,这些智能体能够迅速探索新的知识前沿,以前所未有的速度催生新材料、新药物和新技术。
然而,这个新时代也带来了重大且全新的挑战。人类能力的自动化有望提升生产力,但这些改进也可能导致工作岗位的流失。智能体甚至可能展现出以往被认为是人类专属领域的能力,例如长期问题解决、创新以及对现实世界后果的深刻理解。
此外,尽管对任何人工智能的潜在滥用都存在普遍担忧,但能够长期自主与世界互动以实现长期目标的智能体,可能会带来更高的风险。默认情况下,这减少了人类干预和调解智能体行为的机会,因此对其可信度和责任性提出了极高的要求。摆脱人类数据和人类思维模式也可能使未来的人工智能系统更难以理解。
然而,在承认体验式学习会增加某些安全风险,并且确实需要进一步研究以确保安全过渡到体验时代的同时,我们也应认识到,它也可能带来一些重要的安全益处。
首先,体验式智能体能感知其所处的环境,并且其行为能随着时间的推移适应环境的变化。任何预先编程的系统,包括固定的人工智能系统,都可能意识不到其环境背景,并对其部署于其中的不断变化的世界适应不良。例如,一个关键的硬件可能出现故障,一场大流行可能导致社会的快速变化,或者一项新的科学发现可能引发一连串快速的技术发展。相比之下,体验式智能体可以观察并学会规避故障硬件,适应快速的社会变化,或者接纳并基于新的科学技术进行构建。或许更重要的是,当智能体发现其行为引发了人类的担忧、不满或痛苦时,它可以自适应地调整其行为,以避免这些负面后果。
其次,智能体的奖励函数本身可以通过体验进行调整,例如使用前文描述的双层优化方法。重要的是,这意味着错位的奖励函数通常可以通过试错随着时间的推移逐步得到纠正。例如,在回形针生产耗尽地球所有资源之前,奖励函数可以根据人类担忧的迹象进行修改,而不是盲目地优化某个信号(比如最大化回形针数量)。这类似于人类,人们为彼此设定目标,然后在观察到有人钻制度空子、忽视长期福祉或造成不希望看到的负面后果时调整这些目标;当然,与人类设定目标一样,这也不能保证一劳永逸。
最后,依赖物理体验的进步本质上受到在现实世界中执行行动并观察其结果所需时间的制约。例如,即使有AI辅助设计,新药的开发仍然需要无法在一夜之间完成的现实世界试验。这可能为潜在的人工智能自我改进速度提供一个天然的制约。
结论
体验时代标志着人工智能发展的一个关键时刻。在当今坚实的基础上,超越人类衍生数据的局限,智能体将越来越多地从自身与世界的互动中学习。智能体将通过丰富的观察和行动,自主与环境互动。它们将在终生的体验流中持续适应。它们的目标可以导向任何基于现实的信号组合。此外,智能体将利用强大的非人类推理方式,并构建植根于其行动对环境所产生影响基础上的计划。最终,体验数据的规模和质量将超越人类生成的数据。这一范式转变,伴随着强化学习的算法进步,将在诸多领域解锁超越任何人类所拥有的新能力。
致谢
作者感谢 Thomas Degris、Rohin Shah、Tom Schaul 和 Hado van Hasselt 提出的有益意见和建议。
脚注翻译:
- 强化学习算法是一种通过试错法来学习达成目标的算法,即根据其与环境互动的体验来调整自身行为。这种调整可以通过任何方式实现,例如更新神经网络的权重,或基于环境反馈进行情境适应。
- 体验与人类数据并非完全对立。例如,狗完全从体验中学习,而人类的互动也是其体验的一部分。
- “奖励即足够”假说认为,智能及其相关能力可以从奖励最大化中自然涌现。这可能包括包含人类互动的环境,以及基于人类反馈的奖励。
- 在这种情况下,人们也可以将基于现实的人类反馈视作一个单一的奖励函数,构成了智能体的总体目标。该目标通过构建和优化一个基于丰富的、基于现实的反馈的内在奖励函数来实现最大化。
引用
[1] I. Akkaya, M. Andrychowicz, M. Chociej, M. Litwin, B. McGrew, A. Petron, A. Paino, M. Plappert, G. Powell, R. Ribas, J. Schneider, N. Tezak, J. Tworek, P. Welinder, L. Weng, Q. Yuan, W. Zaremba, and L. Zhang. Solving Rubik’s cube with a robot hand, 2019.
[2] S. Amin, M. Gomrokchi, H. Satija, H. van Hoof, and D. Precup. A survey of exploration methods in reinforcement learning, 2021.
[3] Anthropic. Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku. https://www.anthropic.com/news/3-5-models-and-computer-use, 2024.
[4] C. Berner, G. Brockman, B. Chan, V. Cheung, P. Debiak, C. Dennison, D. Farhi, Q. Fischer, S. Hashme, C. Hesse, R. J´ ozefowicz, S. Gray, C. Olsson, J. Pachocki, M. Petrov, H. P. d. O. Pinto, J. Raiman, T. Salimans, J. Schlatter, J. Schneider, S. Sidor, I. Sutskever, J. Tang, F. Wolski, and S. Zhang. Dota 2 with large scale deep reinforcement learning, 2019.
[5] N. Bostrom. Ethical issues in advanced artificial intelligence. https://nickbostrom.com/ethics/ai, 2003.
[6] N. Brown and T. Sandholm. Superhuman AI for heads-up no-limit poker: Libratus beats top professionals. Science, 359(6374):418–424, 2018.
[7] X. Chen, M. Lin, N. Sch¨ arli, and D. Zhou. Teaching large language models to self-debug, 2023.
[8] N. Chentanez, A. Barto, and S. Singh. Intrinsically motivated reinforcement learning. In L. Saul, Y. Weiss, and L. Bottou, editors, Advances in Neural Information Processing Systems, volume 17. MIT Press, 2004.
[9] P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei. Deep reinforcement learning from human preferences. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017.
[10] DeepSeek AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025.
[11] M. Elsayed, G. Vasan, and A. R. Mahmood. Streaming deep reinforcement learning finally works, 2024.
[12] J. Gehring, K. Zheng, J. Copet, V. Mella, Q. Carbonneaux, T. Cohen, and G. Synnaeve. Rlef: Grounding code llms in execution feedback with reinforcement learning, 2025.
[13] Google DeepMind. Deepmind AI reduces google data centre cooling bill by 40%. https://deepmind.google/discover/blog/deepmind-ai-reduces-google-data-centre-cooling-bill-by-40/, 2016.
[14] Google DeepMind. Gemini: Flash thinking. https://deepmind.google/technologies/gemini/flash-thinking/, 2024.
[15] Google DeepMind. Project Mariner. https://deepmind.google/technologies/project-mariner, 2024.
[16] T. Kojima, S. S. Gu, M. Reid, Y. Matsuo, and Y. Iwasawa. Large language models are zero-shot reasoners. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 22199–22213. Curran Associates, Inc., 2022.
[17] H. Le, Y. Wang, A. D. Gotmare, S. Savarese, and S. C. H. Hoi. CodeRL: Mastering code generation through pretrained models and deep reinforcement learning, 2022.
[18] H. Lightman, V. Kosaraju, Y. Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe. Let’s verify step by step, 2023.
[19] H. Mahdavi, A. Hashemi, M. Daliri, P. Mohammadipour, A. Farhadi, S. Malek, Y. Yazdanifard, A. Khasahmadi, and V. Honavar. Brains vs. bytes: Evaluating llm proficiency in olympiad mathematics, 2025.
[20] H. Masoom, A. Huang, M. Z. Horv´ ath, T. Zahavy, V. Veeriah, E. Wieser, J. Yung, L. Yu, Y. Schroecker, J. Schrittwieser, O. Bertolli, B. Ibarz, E. Lockhart, E. Hughes, M. Rowland, G. Margand, A. Davies, D. Zheng, I. Beˇloshapka, I. von Glehn, Y. Li, F. Pedregosa, A. Velingker, G. Zuˇ zi´ c, O. Nash, B. Mehta, P. Lezeau, S. Mercuri, L. Wu, C. Soenne, T. Murrills, L. Massacci, A. Yang, A. Mandhane, T. Eccles, E. Ayg¨ un, Z. Gong, R. Evans, S. Mokr´ a, A. Barekatain, W. Shang, H. Openshaw, F. Gimeno, D. Silver, and P. Kohli. AI achieves silver-medal standard solving International Mathematical Olympiad problems. https://deepmind.google/discover/blog/ai-solves-imo-problems-at-silver-medal-level/, 2024.
[21] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg, and D. Hassabis. Human-level control through deep reinforcement learning. Nature, 518(7540):529–533, 2015.
[22] M. Moravˇc´ık, M. Schmid, N. Burch, V. Lis`y, D. Morrill, N. Bard, T. Davis, K. Waugh, M. Johanson, and M. Bowling. Deepstack: Expert-level artificial intelligence in heads-up no-limit poker. Science, 356(6337):508–513, 2017.
[23] OpenAI. Openai o1 mini: Advancing cost-efficient reasoning. https://openai.com/index/openai-o1-mini-advancing-cost-efficient-reasoning/, 2024.
[24] OpenAI. Introducing Operator. https://openai.com/index/introducing-operator, 2025.
[25] L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. Christiano, J. Leike, and R. Lowe. Training language models to follow instructions with human feedback, 2022.
[26] J. Perolat, B. D. Vylder, D. Hennes, E. Tarassov, F. Strub, V. de Boer, P. Muller, J. T. Connor, N. Burch, T. Anthony, S. McAleer, R. Elie, S. H. Cen, Z. Wang, A. Gruslys, A. Malysheva, M. Khan, S. Ozair, F. Timbers, T. Pohlen, T. Eccles, M. Rowland, M. Lanctot, J.-B. Lespiau, B. Piot, S. Omidshafiei, E. Lockhart, L. Sifre, N. Beauguerlange, R. Munos, D. Silver, S. Singh, D. Hassabis, and K. Tuyls. Mastering the game of Stratego with model-free multiagent reinforcement learning. Science, 378(6623):990–996, 2022.
[27] I. Petrov, J. Dekoninck, L. Baltadzhiev, M. Drencheva, K. Minchev, M. Balunovi´c, N. Jovanovi´c, and M. Vechev. Proof or bluff? Evaluating llms on 2025 usa math olympiad, 2025.
[28] M. Sadler and N. Regan. Game Changer. New in Chess, 2019.
[29] J. Schrittwieser, I. Antonoglou, T. Hubert, K. Simonyan, L. Sifre, S. Schmitt, A. Guez, E. Lockhart, D. Hassabis, T. Graepel, T. P. Lillicrap, and D. Silver. Mastering Atari, Go, chess and shogi by planning with a learned model. Nature, 588:604–609, 2019.
[30] D. Schurmanns. Memory augmented large language models are computationally universal. arXiv preprint arXiv:2501.12948, 2023.
[31] D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. Van Den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot, S. Dieleman, D. Grewe, J. Nham, N. Kalchbrenner, I. Sutskever, T. Lillicrap, M. Leach, K. Kavukcuoglu, T. Graepel, and D. Hassabis. Mastering the game of Go with deep neural networks and tree search. Nature, 529(7587):484–489, 2016.
[32] D. Silver, T. Hubert, J. Schrittwieser, I. Antonoglou, M. Lai, A. Guez, M. Lanctot, L. Sifre, D. Kumaran, T. Graepel, T. Lillicrap, K. Simonyan, and D. Hassabis. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science, 362(6419):1140–1144, 2018.
[33] D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. Baker, M. Lai, A. Bolton, Y. Chen, T. Lillicrap, F. Hui, L. Sifre, G. van den Driessche, T. Grapel, and D. Hassabis. Mastering the game of go without human knowledge. Nature, 550(7676):354–359, 2017.
[34] D. Silver, S. Singh, D. Precup, and R. S. Sutton. Reward is enough. Artificial Intelligence, 299:103535, 2021.
[35] R. S. Sutton. Learning to predict by the methods of temporal differences. Machine Learning, 3:9–44, 1988.
[36] R. S. Sutton. Integrated architectures for learning, planning, and reacting based on approximating dynamic programming. In Proceedings of the Seventh International Conference on Machine Learning, pages 216–224. Morgan Kaufmann, 1990.
[37] R. S. Sutton and A. G. Barto. Reinforcement Learning: An Introduction. The MIT Press, second edition, 2018.
[38] R. S. Sutton, D. Precup, and S. Singh. Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning. Artificial Intelligence, 112(1-2):181–211, 1999.
[39] G. Tesauro. TD-Gammon, a self-teaching backgammon program, achieves master-level play. Neural Computation, 6(2):215–219, 1994.
[40] O. Vinyals, I. Babuschkin, W. M. Czarnecki, M. Mathieu, A. Dudzik, J. Chung, D. Choi, R. Powell, T. Ewalds, P. Georgiev, J. Oh, D. Horgan, M. Kroiss, I. Danihelka, A. Huang, L. Sifre, T. Cai, J. P. Agapiou, M. Jaderberg, A. S. Vezhnevets, R. Leblond, T. Pohlen, V. Dalibard, D. Budden, Y. Sulsky, J. Molloy, T. L. Paine, C. Gulcehre, Z. Wang, T. Pfaff, Y. Wu, R. Ring, D. Yogatama, D. W¨ unsch, K. McKinney, O. Smith, T. Schaul, T. P. Lillicrap, K. Kavukcuoglu, D. Hassabis, C. Apps, and D. Silver. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 575:350–354, 2019.
[41] P. R. Wurman, S. Barrett, K. Kawamoto, J. MacGlashan, K. Subramanian, T. J. Walsh, R. Capobianco, A. Devlic, F. Eckert, F. Fuchs, L. Gilpin, P. Khandelwal, V. Kompella, H. Lin, P. MacAlpine, D. Oller, T. Seno, C. Sherstan, M. D. Thomure, H. Aghabozorgi, L. Barrett, R. Douglas, D. Whitehead, P. D¨ urr, P. Stone, M. Spranger, and H. Kitano. Outracing champion Gran Turismo drivers with deep reinforcement learning. Nature, 602(7896):223–228, 2022.
[42] M. S. Yang, D. Schuurmans, P. Abbeel, and O. Nachum. Chain of thought imitation with procedure cloning. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 36366–36381. Curran Associates, Inc., 2022.
[43] S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao. React: Synergizing reasoning and acting in large language models. In 11th International Conference on Learning Representations, 2023.
[44] E. Zelikman, J. M. Mu, N. D. Goodman, and G. Poesia. Star: Bootstrapping reasoning with reasoning. Advances in Neural Information Processing Systems, 35:24170–24184, 2022.
[45] Y. Zhou. Rethinking Opening Strategy: AlphaGo’s Impact on Pro Play. CreateSpace Independent, 2018.



